

[ad_1]
Как наделить компьютер способностью самостоятельно учиться, анализировать данные и принимать решения? Ответ: используя машинное обучение с подкреплением. Давайте разберемся, как эта захватывающая технология переворачивает представление о возможностях искусственного интеллекта.
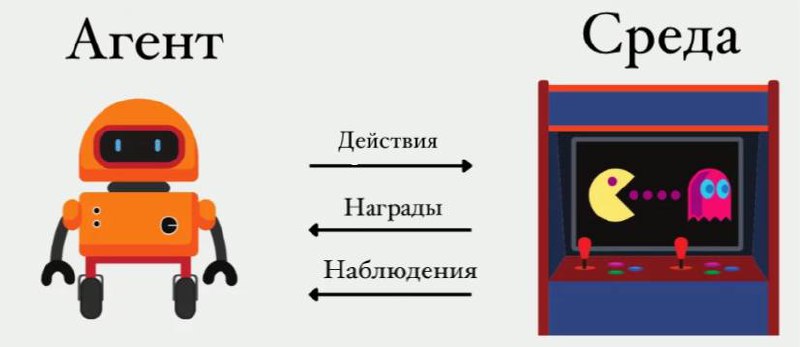
Обучение с подкреплением — это способ машинного обучения, в котором система (также именуемая как агент) вырабатывает алгоритм решения задачи методом проб и ошибок. Основная идея заключается в том, что она взаимодействует со средой (тренировочной ситуацией) и, параллельно обучаясь, получает вознаграждение за выполнение верных действий. За каждое хорошее действие агент заслуживает положительный бонус, фидбэк, а за каждое плохое — отрицательный. Таким образом, метод основан на обратной связи.
Всего же выделяют четыре основных типа машинного обучения:
1. Обучение с учителем (контролируемое обучение)
2. Обучение без учителя (неконтролируемое обучение)
3. Обучение с частичным привлечением учителя
4. Обучение с подкреплением
Для обучения роботов и интеллектуальных систем разработчики могут использовать и несколько методов сразу.
Какие задачи решает эта технология
Основной сложностью обучения машин является то, что для этого требуется огромное количество данных. Считается, что чем сложнее модель, тем больше информации необходимо. Но данные могут или быть недоступными, или не существовать вовсе. Кроме того, полученная информация рискует оказаться ненадежной: в ней могут содержаться ложные, отсутствующие или устаревшие факты.
Для наилучшей оптимизации машины должны научиться выполнять действия самостоятельно. Все эти проблемы решаются, когда на помощь приходит обучение с подкреплением.

Алгоритмы обучения с подкреплением извлекают уроки из результатов и помогают машине выбрать, какое действие предпринять в дальнейшем. После каждого шага агент получает обратную связь, которая помогает ему определить, был ли сделанный им выбор правильным, нейтральным или неправильным. На первое место встает результат, качество которого улучшается посредством практики.
Где нужно обучение с подкреплением
Обучение с подкреплением применяется в различных областях, где агенты могут учиться и совершенствовать свои действия на основе опыта, что приводит к оптимизации процессов, повышению производительности и качества принимаемых решений.
В робототехнике обучение с подкреплением позволяет машинам осваивать различные навыки и оптимизировать свои действия в реальном времени. Например, на конвейерной линии робот может обучиться эффективно собирать продукты, учитывая различные формы и размеры.
Технология также помогает при разработке таких автономных систем, как беспилотные автомобили и дроны. За счет системы вознаграждений и санкций агенты могут учиться адаптироваться к окружающей среде и принимать решения о безопасности и эффективности передвижения.
В программировании этот метод используется для оптимизации гиперпараметров алгоритмов машинного обучения или выбора наилучших моделей для конкретных задач. Агенты могут непрерывно пробовать разные настройки и улучшать производительность моделей.

В бизнесе обучение с подкреплением может использоваться для создания стратегических рекомендаций. Например, в финансовой сфере агенты могут учиться принимать решения о портфеле инвестиций и реагировать на колебания на рынке. Нейросети на базе глубокого обучения с подкреплением эффективны в прогнозировании динамики цен на акции, так как такие модели быстро адаптируются в постоянно меняющейся среде.

Обучение с подкреплением позволяет улучшить рекомендательные системы и в сфере образования. Например, университетские ресурсы могут предлагать студентам индивидуализированные материалы для дополнительного обучения, учитывая их предпочтения и академические цели.
Обучение с подкреплением: примеры
Технология давно используется для создания компьютерных программ, способных сражаться с реальными игроками, например с мировыми шахматистами. Так, компьютер Deep Blue от IBM победил Гарри Каспарова в 1997 году.
Программа AlphaGo, обученная тем же методом подразделением Google DeepMind, смогла в 2016-м одолеть чемпиона мира по Го, хотя игра считается более сложной, чем шахматы, из-за большого числа возможных позиций. А в прошлом году в DeepMind научили играть в футбол цифровых гуманоидов.
Между тем в 2023-м система искусственного интеллекта Swift AI для управления беспилотниками одержала безоговорочную победу над людьми в гонке дронов на высоких скоростях в Швейцарии.
Как ИИ удается обыгрывать человека? Обучение с подкреплением позволяет интеллектуальным агентам учиться самостоятельно принимать решения, которые основываются на многократном опыте и мотивации в виде награды за успешное прохождение. Это делает его мощным методом в разных областях, где необходимо обучить систему взаимодействовать с окружающей средой. Обучение с подкреплением можно также использовать, моделируя самые разные ситуации.

Например, можно создать обстановку, в которой агент должен перейти с одной стороны дороги на другую, при этом не столкнувшись ни с одной машиной. За успешную попытку миновать препятствие агент будет получать бонус, условно +5. Если же агент сталкивается с машиной, то он получает штраф, соответственно, -5. Спустя множество попыток система начнет вырабатывать стратегию для успешного выполнения задачи. Чем больше шагов предпринимается, тем качественнее окажутся действия агента, так как модель будет постоянно улучшать алгоритм с целью получить награду.
При этом обучение с подкреплением порой работает гораздо быстрее других методов. Например, в 2021 году роботы-уборщики Everyday Robots в кампусе Google освоили сложную задачу «открыть дверь» всего за день. По словам разработчиков, это могло занять около четырех месяцев программирования.
Будущее технологии
По прогнозам, обучение с подкреплением будет играть все большую роль в развитии искусственного интеллекта. Единственный недостаток на сегодняшний день в том, что агентам обучения требуется время, чтобы постепенно достигать цели посредством взаимодействия со своим окружением. Однако, несмотря ни на что, ожидается, что различные отрасли продолжат изучать потенциал обучения с подкреплением.
Ученые из Google DeepMind предположили, что обучение с подкреплением может привести текущее состояние ИИ (часто называемое узким ИИ) к его теоретической окончательной форме искусственного общего интеллекта. Они верят, что машины с помощью обучения с подкреплением в конечном итоге станут разумными и будут работать независимо от контроля человека.
Алексей АЛТЫНБАЕВ
Изображения: сгенерированы ИИ (Kandinsky); Data Basecamp; Freepik
[ad_2]
Источник

{kind=link}