

[ad_1]
В стремительно развивающемся мире больших языковых моделей (LLMs) появилась новая мощная модель – DBRX, созданная Databricks. Эта модель открытого типа демонстрирует передовую производительность по широкому кругу бенчмарков, составляя конкуренцию даже таким гигантам индустрии, как GPT-4 от OpenAI.
DBRX является значимым этапом в демократизации искусственного интеллекта, предоставляя исследователям, разработчикам и предприятиям открытый доступ к высококлассной языковой модели. Но что такое DBRX и что делает её такой особенной? В этом техническом обзоре мы рассмотрим инновационную архитектуру, процесс обучения и ключевые возможности, которые вывели DBRX на передний план среди открытых LLM.
Рождение DBRX
Создание DBRX было мотивировано миссией Databricks сделать данные интеллектуальными для всех предприятий. Как лидер в сфере платформ аналитики данных, Databricks узнала огромный потенциал LLMs и приступила к разработке модели, способной соперничать или даже превосходить производительность собственнических решений.
После месяцев интенсивных исследований и разработок, а также многомиллионных инвестиций команда Databricks достигла прорыва с DBRX. Впечатляющая производительность модели по широкому спектру бенчмарков, включая понимание языка, программирование и математику, окончательно утвердила её как новый эталон среди открытых LLMs.
Инновационная архитектура
Сила смешения экспертов В основе исключительной производительности DBRX лежит её инновационная архитектура смешения экспертов (MoE). Этот передовой дизайн отходит от традиционных плотных моделей, принимая разреженный подход, который повышает эффективность предварительного обучения и скорость вывода.
В рамках MoE только выбранная группа компонентов, называемых «экспертами», активируется для каждого ввода. Эта специализация позволяет модели решать широкий спектр задач с большей ловкостью, оптимизируя при этом использование вычислительных ресурсов.
DBRX развивает эту концепцию ещё дальше с его детализированной архитектурой MoE. В отличие от некоторых других моделей MoE, которые используют меньшее количество больших экспертов, DBRX задействует 16 экспертов, при этом четыре эксперта активны для любого заданного ввода. Этот дизайн обеспечивает поразительные 65 раз больше возможных комбинаций экспертов, непосредственно способствуя превосходной производительности DBRX.
DBRX отличается несколькими инновационными функциями:
- Вращающиеся позиционные кодировки (RoPE): улучшают понимание позиций токенов, что критически важно для генерации контекстуально точного текста.
- Вентильные линейные блоки (GLU): вводят механизм шлюза, который улучшает способность модели эффективно учиться на сложных шаблонах.
- Группированное внимание запросов (GQA): повышает эффективность модели, оптимизируя механизм внимания.
- Продвинутая токенизация: использует токенизатор GPT-4 для более эффективной обработки входов. Архитектура MoE особенно хорошо подходит для масштабных языковых моделей, поскольку позволяет более эффективно масштабировать и лучше использовать вычислительные ресурсы. Распределяя процесс обучения по нескольким специализированным подсетям, DBRX может эффективно распределять данные и вычислительную мощность для каждой задачи, обеспечивая высококачественный вывод и оптимальную эффективность.
Обширные тренировочные данные и эффективная оптимизация Хотя архитектура DBRX несомненно впечатляет, истинная мощь модели заключается в тщательном процессе обучения и огромном объёме данных, к которым она была подвергнута. DBRX была предварительно обучена на удивительных 12 триллионах токенов текста и кода, тщательно отобранных для обеспечения высокого качества и разнообразия.
Данные для обучения обрабатывались с помощью набора инструментов Databricks, включая Apache Spark для обработки данных, Unity Catalog для управления данными и управления ими, а также MLflow для отслеживания экспериментов. Этот комплексный набор инструментов позволил команде Databricks эффективно управлять, изучать и уточнять массивный набор данных, заложивший основу для исключительной производительности DBRX.
Для дальнейшего повышения возможностей модели Databricks использовала динамичное учебное учебное пособие, новаторски меняя смесь данных во время обучения. Эта стратегия позволила каждому токену быть эффективно обработанным с использованием активных 36 миллиардов параметров, что привело к созданию более универсальной и адаптивной модели.
Более того, процесс обучения DBRX был оптимизирован для повышения эффективности, благодаря использованию собственных инструментов и библиотек Databricks, включая Composer, LLM Foundry, MegaBlocks и Streaming. Применяя техники, такие как учебное обучение и оптимизированные стратегии оптимизации, команде удалось достичь почти четырехкратного улучшения вычислительной эффективности по сравнению с предыдущими моделями.
Обучение и архитектура DBRX обучалась с использованием модели предсказания следующего токена на колоссальном наборе данных из 12 триллионов токенов, акцентируя внимание как на тексте, так и на коде. Считается, что этот тренировочный набор значительно эффективнее тех, которые использовались в предыдущих моделях, обеспечивая богатое понимание и способность реагировать на разнообразные запросы.
Архитектура DBRX не только свидетельствует о техническом мастерстве Databricks, но также подчеркивает её применение в различных секторах. От улучшения взаимодействия с чат-ботами до выполнения сложных задач анализа данных, DBRX может быть интегрирована в разнообразные области, требующие тонкого понимания языка.
На удивление, DBRX Instruct даже конкурирует с некоторыми из самых передовых закрытых моделей на рынке. Согласно измерениям Databricks, она превосходит GPT-3.5 и конкурирует с Gemini 1.0 Pro и Mistral Medium по различным бенчмаркам, включая общие знания, здравый смысл, программирование и математическое рассуждение.
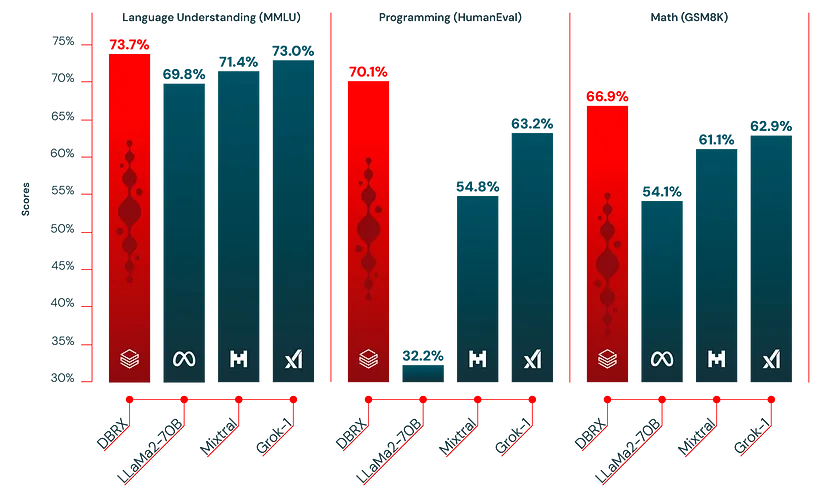
Например, на бенчмарке MMLU, который измеряет понимание языка, DBRX Instruct достигла результат в 73.7%, превзойдя заявленный результат GPT-3.5 в 70.0%. На бенчмарке HellaSwag по здравому смыслу DBRX Instruct набрала впечатляющие 89.0%, превзойдя 85.5% у GPT-3.5.
DBRX Instruct действительно блестит, достигая замечательной точности в 70.1% на бенчмарке HumanEval, превосходя не только GPT-3.5 (48.1%), но и специализированную модель CodeLLaMA-70B Instruct (67.8%).
Эти исключительные результаты подчеркивают универсальность DBRX и её способность превосходить в широком спектре задач, от понимания естественного языка до сложного программирования и решения математических задач.
Эффективный вывод и масштабируемость Одним из ключевых преимуществ архитектуры MoE DBRX является её эффективность во время вывода. Благодаря разреженной активации параметров DBRX может достигать пропускной способности вывода, которая в два-три раза быстрее, чем у плотных моделей с тем же общим количеством параметров.
По сравнению с LLaMA2-70B, популярной открытой LLM, DBRX не только демонстрирует более высокое качество, но также имеет почти вдвое большую скорость вывода, несмотря на то, что количество активных параметров примерно вдвое меньше. Эта эффективность делает DBRX привлекательным выбором для развертывания в широком спектре приложений, от создания контента до анализа данных и далее.
Более того, Databricks разработала надежный стек обучения, позволяющий предприятиям обучать свои собственные модели класса DBRX с нуля или продолжать обучение на основе предоставленных контрольных точек. Эта возможность позволяет предприятиям использовать весь потенциал DBRX и адаптировать его к своим конкретным потребностям, дальнейше демократизируя доступ к передовым технологиям LLM.
Разработка модели DBRX Databricks отмечает значительный прогресс в области машинного обучения, особенно благодаря использованию инновационных инструментов из сообщества открытого программного обеспечения. Это путешествие по разработке значительно зависит от двух ключевых технологий: библиотеки MegaBlocks и системы Fully Sharded Data Parallel (FSDP) от PyTorch.
MegaBlocks: Повышение эффективности MoE
Библиотека MegaBlocks решает проблемы, связанные с динамической маршрутизацией в слоях смешения экспертов (MoEs), обычное препятствие при масштабировании нейронных сетей. Традиционные рамки часто налагают ограничения, которые либо снижают эффективность модели, либо идут на компромисс с качеством модели. Однако MegaBlocks переопределяет вычисление MoE через блочно-разреженные операции, которые умело управляют внутренней динамикой в MoEs, избегая этих компромиссов.
Этот подход не только сохраняет целостность токенов, но также хорошо сочетается с современными возможностями GPU, обеспечивая до 40% более быстрые времена обучения по сравнению с традиционными методами. Такая эффективность критически важна для обучения моделей, таких как DBRX, которые в значительной степени зависят от передовых архитектур MoE для эффективного управления их обширными наборами параметров.
PyTorch FSDP: Масштабирование крупных моделей
Система Fully Sharded Data Parallel (FSDP) от PyTorch представляет собой надежное решение для обучения исключительно крупных моделей, оптимизируя разделение и распределение параметров по нескольким вычислительным устройствам. Совместно разработанная с ключевыми компонентами PyTorch, FSDP интегрируется бесшовно, предлагая интуитивно понятный пользовательский опыт, аналогичный локальным тренировочным настройкам, но в гораздо большем масштабе.
Дизайн FSDP умело решает несколько критических проблем:
- Пользовательский опыт: он упрощает пользовательский интерфейс, несмотря на сложные процессы на бэкенде, делая его более доступным для широкого использования.
- Гетерогенность оборудования: он адаптируется к различным аппаратным средам для оптимального использования ресурсов.
- Использование ресурсов и планирование памяти: FSDP повышает использование вычислительных ресурсов, минимизируя накладные расходы на память, что имеет решающее значение для обучения моделей, работающих в масштабе DBRX. FSDP не только поддерживает более крупные модели, чем это было возможно ранее в рамках рамки распределенного параллельного обучения по данным, но также обеспечивает почти линейную масштабируемость в плане пропускной способности и эффективности. Эта возможность оказалась необходимой для Databricks’ DBRX, позволяя ей масштабироваться по нескольким графическим процессорам, эффективно управляя её огромным числом параметров.
Доступность и интеграции В соответствии с миссией по продвижению открытого доступа к ИИ Databricks сделала DBRX доступной через несколько каналов. Веса как базовой модели (DBRX Base), так и донастроенной модели (DBRX Instruct) размещены на популярной платформе Hugging Face, позволяя исследователям и разработчикам легко загружать и работать с моделью.
Кроме того, репозиторий модели DBRX доступен на GitHub, обеспечивая прозрачность и позволяя дальнейшее исследование и настройку кода модели.
Пропускная способность вывода для различных конфигураций модели на нашей оптимизированной инфраструктуре обслуживания с использованием NVIDIA TensorRT-LLM с 16-битной точностью с лучшими оптимизационными флагами, которые мы могли найти.
Для клиентов Databricks DBRX Base и DBRX Instruct удобно доступны через API моделей Databricks Foundation, что позволяет легко интегрировать их в существующие рабочие процессы и приложения. Это не только упрощает процесс развертывания, но также обеспечивает управление данными и безопасность для чувствительных случаев использования.
Более того, DBRX уже интегрирована в несколько сторонних платформ и сервисов, таких как You.com и Perplexity Labs, расширяя её охват и потенциальные области применения. Эти интеграции демонстрируют растущий интерес к DBRX и её возможностям, а также увеличивающееся внедрение открытых LLM в различных отраслях и случаях использования.
Возможности обработки длинных контекстов и генерация с использованием восстановленной информации Одной из выдающихся особенностей DBRX является её способность обрабатывать входные данные с длинным контекстом, с максимальной длиной контекста 32 768 токенов. Эта возможность позволяет модели обрабатывать и генерировать текст на основе обширной контекстной информации, что делает её подходящей для задач, таких как резюмирование документов, ответы на вопросы и извлечение информации.
На бенчмарках, оценивающих производительность с длинным контекстом, таких как KV-Pairs и HotpotQAXL, DBRX Instruct превзошла GPT-3.5 Turbo по различным длинам последовательностей и позициям контекста.
DBRX превосходит установленные открытые модели по пониманию языка (MMLU), программированию (HumanEval) и математике (GSM8K). DBRX превосходит установленные открытые модели по пониманию языка (MMLU), программированию (HumanEval) и математике (GSM8K).
Ограничения и будущая работа Хотя DBRX представляет собой значительное достижение в области открытых LLM, важно признать её ограничения и области для будущего улучшения. Как и любая модель ИИ, DBRX может производить неточные или предвзятые ответы в зависимости от качества и разнообразия её обучающих данных.
Кроме того, хотя DBRX преуспевает в выполнении задач общего назначения, некоторые специализированные приложения могут потребовать дополнительной донастройки или специализированного обучения для достижения оптимальной производительности. Например, в сценариях, где точность и верность имеют решающее значение, Databricks рекомендует использовать техники генерации с использованием восстановленной информации (RAG), чтобы улучшить вывод модели.
Кроме того, текущий тренировочный набор данных DBRX в основном состоит из контента на английском языке, что потенциально ограничивает её производительность по задачам на других языках. В будущих итерациях модели могут быть включены данные для обучения, охватывающие более разнообразный диапазон языков и культурных контекстов.
Databricks стремится постоянно улучшать возможности DBRX и устранять её ограничения. В будущих работах будет сосредоточено внимание на повышении производительности модели, масштабируемости и удобстве использования в различных приложениях и сценариях использования, а также на изучении техник, направленных на устранение потенциальных предвзятостей и содействие этичному использованию ИИ.
Кроме того, компания планирует дальнейшее усовершенствование процесса обучения, используя передовые методы, такие как распределенное обучение и методы, обеспечивающие конфиденциальность данных, для обеспечения конфиденциальности данных и безопасности.
Дорога впереди DBRX представляет собой значительный шаг вперед в демократизации разработки ИИ. Она предвещает будущее, где каждое предприятие имеет возможность контролировать свои данные и свою судьбу в новом мире генеративного ИИ.
Открывая DBRX и предоставляя доступ к тем же инструментам и инфраструктуре, которые использовались для её создания, Databricks дает предприятиям и исследователям возможность разрабатывать свои собственные передовые модели Databricks, адаптированные к их конкретным потребностям.
Через платформу Databricks клиенты могут использовать набор инструментов компании для обработки данных, включая Apache Spark, Unity Catalog и MLflow, для курирования и управления своими тренировочными данными. Затем они могут использовать оптимизированные библиотеки обучения Databricks, такие как Composer, LLM Foundry, MegaBlocks и Streaming, для эффективного и масштабируемого обучения своих собственных моделей класса DBRX.
Эта демократизация разработки ИИ может открыть новую волну инноваций, поскольку предприятия получают возможность использовать мощь больших языковых моделей для широкого спектра приложений, от создания контента и анализа данных до поддержки принятия решений и далее.
Более того, способствуя открытому и сотрудническому экосистемному подходу вокруг DBRX, Databricks стремится ускорить темпы исследований и разработок в области больших языковых моделей. По мере того как больше организаций и лиц будут вносить свой вклад своим опытом и знаниями, коллективные знания и понимание этих мощных систем ИИ будут продолжать расти, прокладывая путь для еще более продвинутых и способных моделей в будущем.
Заключение DBRX – это изменение правил игры в мире открытых больших языковых моделей. С её инновационной архитектурой смешения экспертов, обширными тренировочными данными и передовой производительностью она установила новый стандарт того, что возможно с открытыми LLM.
Открыв доступ к передовым технологиям ИИ, DBRX дает исследователям, разработчикам и предприятиям возможность исследовать новые горизонты в области обработки естественного языка, создания контента, анализа данных и за его пределами. По мере того как Databricks продолжает усовершенствовать и улучшать DBRX, потенциальные приложения и влияние этой мощной модели действительно не ограничены.
Источник: Inside DBRX: Databricks Unleashes Powerful Open Source LLM
[ad_2]
Источник

{kind=link}