

[ad_1]
Сфера генеративного искусственного интеллекта быстро развивается с появлением больших мультимодальных моделей (LMM). Эти модели меняют способ нашего взаимодействия с системами искусственного интеллекта, позволяя нам использовать в качестве входных данных как изображения, так и текст. GPT-4 Vision от OpenAI является ярким примером этой технологии, но ее закрытый и коммерческий характер может ограничивать ее использование в определенных приложениях.
Тем не менее, сообщество открытого исходного кода принимает вызов: LLaVA 1.5 становится многообещающим проектом альтернатив GPT-4 Vision с открытым исходным кодом.
LLaVA 1.5 сочетает в себе несколько генеративных компонентов искусственного интеллекта и была доработана для создания модели с эффективными вычислениями, которая выполняет различные задачи с высокой точностью. Хотя это не единственный LMM с открытым исходным кодом, его вычислительная эффективность и высокая производительность могут задать новое направление для будущих исследований LMM.
Как работают LMM
LMM обычно используют архитектуру, состоящую из нескольких уже существующих компонентов: предварительно обученной модели для кодирования визуальных функций, предварительно обученной модели большого языка (LLM) для понимания пользовательских инструкций и генерации ответов, а также кросс-модального соединителя языка видения. для согласования кодировщика изображения и языковой модели.
Обучение LMM, следующего инструкциям, обычно включает в себя двухэтапный процесс. На первом этапе, предварительном обучении выравниванию изображения и языка, используются пары изображение-текст для выравнивания визуальных функций с пространством встраивания слов языковой модели. Второй этап — настройка визуальных инструкций — позволяет модели следовать подсказкам, включающим визуальный контент, и реагировать на них. Этот этап часто является сложным из-за его трудоемкого характера и необходимости иметь большой набор данных с тщательно подобранными примерами.
Что делает LLaVA эффективным?
LLaVA 1.5 использует модель CLIP (контрастный язык – предварительное обучение изображения) в качестве визуального кодировщика. CLIP, разработанный OpenAI в 2021 году, учится связывать изображения и текст путем обучения на большом наборе данных пар изображение-описание. Он используется в продвинутых моделях преобразования текста в изображение, таких как DALL-E 2.
Языковой моделью LLaVA является Vicuna, версия модели LLaMA с открытым исходным кодом Meta, настроенная для следования инструкциям. Исходная модель LLaVA использовала только текстовые версии ChatGPT и GPT-4 для создания обучающих данных для визуальной тонкой настройки. Исследователи предоставили LLM описания изображений и метаданные, что побудило его создавать диалоги, вопросы, ответы и решать задачи на основе содержания изображения. Этот метод позволил создать 158 000 обучающих примеров для обучения LLaVA визуальным инструкциям и оказался очень эффективным.
LLaVA 1.5 совершенствует оригинал, соединяя языковую модель и кодировщик изображения через многослойный перцептрон (MLP), простую модель глубокого обучения, в которой все нейроны полностью связаны. Исследователи также добавили к обучающим данным несколько визуальных наборов данных для ответов на вопросы с открытым исходным кодом, масштабировали разрешение входного изображения и собрали данные из ShareGPT, онлайн-платформы, где пользователи могут делиться своими разговорами с ChatGPT. Все данные обучения состояли примерно из 600 000 примеров и заняли около дня на восьми графических процессорах A100 и стоили всего несколько сотен долларов.
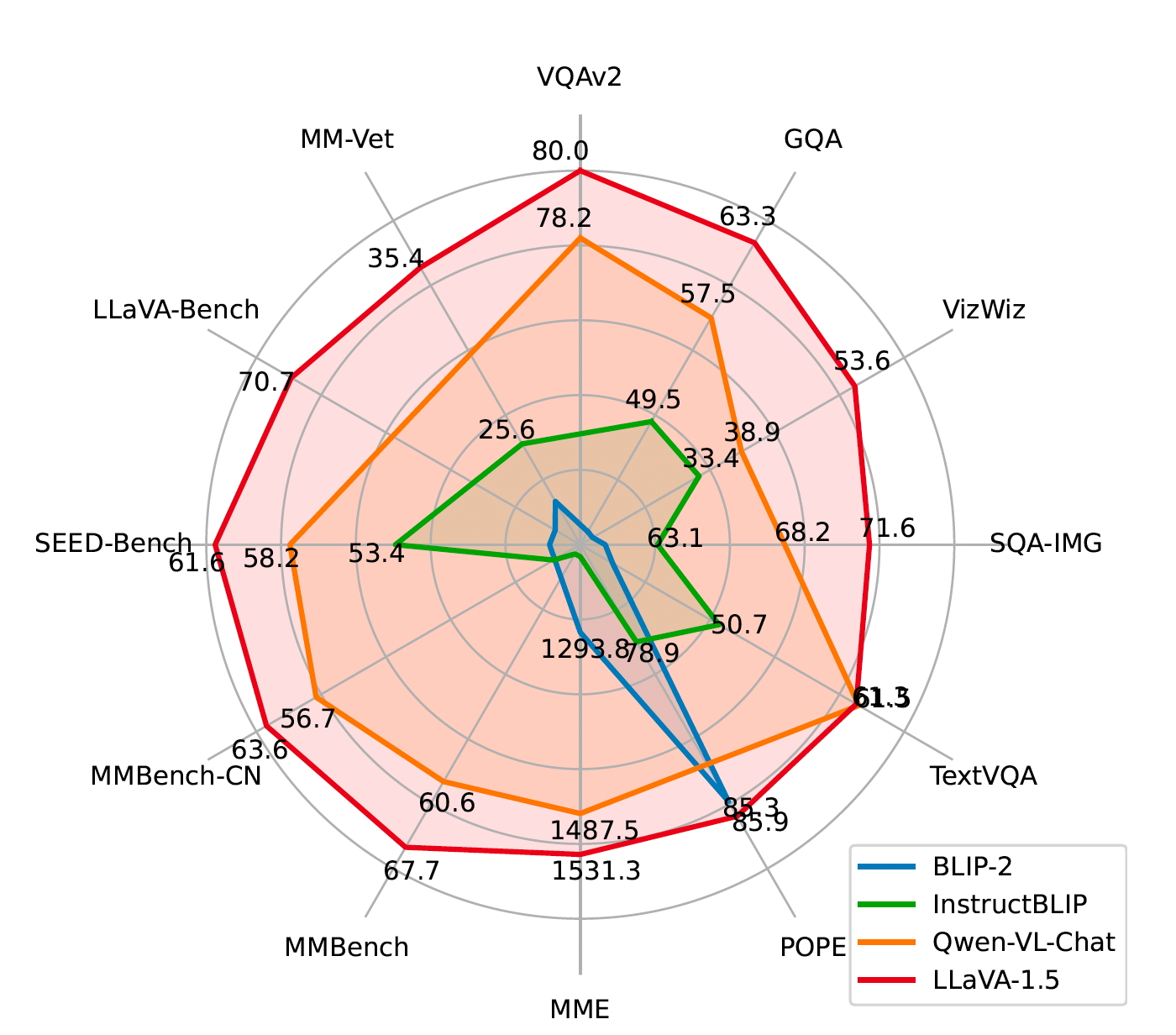
По мнению исследователей, LLaVA 1.5 превосходит другие LMM с открытым исходным кодом в 11 из 12 мультимодальных тестов. (Следует отметить, что измерение производительности LMM является сложной задачей, и тесты тестов могут не обязательно отражать производительность в реальных приложениях.)

Будущее LLM с открытым исходным кодом
Доступна онлайн-демонстрация LLaVA 1.5, демонстрирующая впечатляющие результаты небольшой модели, которую можно обучать и запускать при ограниченном бюджете. Код и набор данных также доступны, что способствует дальнейшему развитию и настройке. Пользователи делятся интересными примерами того, как LLaVA 1.5 может обрабатывать сложные запросы.
Однако в LLaVA 1.5 есть один нюанс. Поскольку он был обучен на данных, сгенерированных ChatGPT, его нельзя использовать в коммерческих целях из-за условий использования ChatGPT, которые не позволяют разработчикам использовать его для обучения конкурирующих коммерческих моделей.
Создание продукта AI также сопряжено со многими проблемами, выходящими за рамки обучения модели, и LLaVA пока не является соперником GPT-4V, который удобен, прост в использовании и интегрирован с другими инструментами OpenAI, такими как DALL-E 3 и внешними плагинами. .
Однако LLaVA 1.5 имеет несколько привлекательных особенностей, в том числе экономичность и масштабируемость создания обучающих данных для настройки визуальных инструкций с помощью LLM. Этой цели могут служить несколько альтернатив ChatGPT с открытым исходным кодом, и это лишь вопрос времени, когда другие повторят успех LLaVA 1.5 и разовьют его в новых направлениях, включая разрешительное лицензирование и модели для конкретных приложений.
LLaVA 1.5 — это лишь проблеск того, чего мы можем ожидать в ближайшие месяцы от LMM с открытым исходным кодом. Поскольку сообщество открытого исходного кода продолжает внедрять инновации, мы можем ожидать появления более эффективных и доступных моделей, которые еще больше демократизируют новую волну генеративных технологий искусственного интеллекта.
[ad_2]
Источник

{kind=link}